Java 基础-常见面试题
本文最后更新于 2024-05-25,文章内容可能已经过时。
Java 基础-常见面试题(Java Fundamentals - Common Interview Questions)
面向对象的三大特征
封装
在 Java 中,封装主要是通过使用类的成员变量(属性)和成员方法(行为)来实现。。一般来说,我们会设置属性为私有(private),这样外部就无法直接访问和修改我的属性。然后,我们会提供一些公共的方法来获取(getter)和设置(setter)这些属性,即访问器方法。
例如:
public class Student {
// 私有属性
private String name;
private int age;
// 公共的getter方法
public String getName() {
return name;
}
// 公共的setter方法
public void setName(String name) {
this.name = name;
}
// 公共的getter方法
public int getAge() {
return age;
}
// 公共的setter方法
public void setAge(int age) {
if (age >= 0 && age <= 100) {
this.age = age;
} else {
System.out.println("Invalid age");
}
}
}
继承
我们创建一个类(称为子类或派生类),该类继承另一个类(称为父类或基类)的属性和方法。通过继承呢,子类可以重用父类的代码,从而避免重复编写相同的代码。这样可以提高代码的可重用性,促进代码的组织以及管理。
在 Java 中,可以使用extends关键字来实现继承。子类可以继承父类的所有非私有成员(属性、方法),并且子类也可以添加自己的成员,或重写父类方法。
例如:
// 父类
class Animal {
private String name;
public Animal(String name) {
this.name = name;
}
public void makeSound() {
System.out.println("The animal makes a sound");
}
public String getName() {
return name;
}
}
// 子类继承自父类
class Dog extends Animal {
public Dog(String name) {
// 调用父类的构造方法
super(name);
}
// 重写父类的方法
@Override
public void makeSound() {
System.out.println("The dog barks");
}
// 子类特有的方法
public void fetchStick() {
System.out.println("The dog fetches a stick");
}
}
// 主类,测试继承
public class InheritanceDemo {
public static void main(String[] args) {
Dog dog = new Dog("Buddy");
dog.makeSound(); // 输出: The dog barks
System.out.println(dog.getName()); // 输出: Buddy
dog.fetchStick(); // 输出: The dog fetches a stick
}
}
多态
指的是同一操作作用于不同的对象,可以产生不同的执行结果。
多态性可以通过两种方式体现:
- 编译时多态性:方法的重载。在同一个类中,可以声明多个同名但参数个数、类型或顺序不同的方法。在编译时期,根据参数的不同来判定采用的方法。
- 运行时多态性:方法的重写和父类引用指向子类对象。派生类可以声明与从基类继承的方法签名一致的方法,即重写方法。在程序运行时,根据运行时对象的类型来调用相应类实现(重写)的方法。
例如:
// 基类
class Shape {
void draw() {
System.out.println("Drawing a generic shape");
}
}
// 子类1
class Circle extends Shape {
@Override
void draw() {
System.out.println("Drawing a circle");
}
}
// 子类2
class Rectangle extends Shape {
@Override
void draw() {
System.out.println("Drawing a rectangle");
}
}
// 主类,测试多态
public class PolymorphismDemo {
public static void main(String[] args) {
// 创建子类对象
Shape circle = new Circle();
Shape rectangle = new Rectangle();
// 调用draw方法,展示多态性
circle.draw(); // 输出: Drawing a circle
rectangle.draw(); // 输出: Drawing a rectangle
// 用数组来存储不同形状的对象,并调用它们的draw方法
Shape[] shapes = new Shape[2];
shapes[0] = new Circle();
shapes[1] = new Rectangle();
for (Shape shape: shapes) {
shape.draw(); // 分输出: Drawing a circle 和 Drawing a rectangle
}
}
}
抽象类和接口有什么相同点和区别?
💞相同点:
- 都不能被实例化。
- 都可以包含抽象方法。
- 都可以有默认实现的方法(在 Java8 中使用
default关键字在接口中定义)
💕区别:
- 定义方式:接口使用
interface关键字,抽象类使用abstract class关键字。 - 方法实现:接口方法默认是抽象的,没有具体实现。抽象类方法可以是抽象的,也可以是实现的。
- 字段定义:接口只能定义常量(如
public static final),抽象类可以定义普通的成员变量。 - 构造器:接口没有构造器,抽象类可以有构造器。主要用于被子类调用,进行初始化。
- 实现和继承:一个类可以实现多个接口,但只能基础一个抽象类。
- 访问控制:接口默认方法是
public,抽象类可以有不同的修饰符(如public、protected)
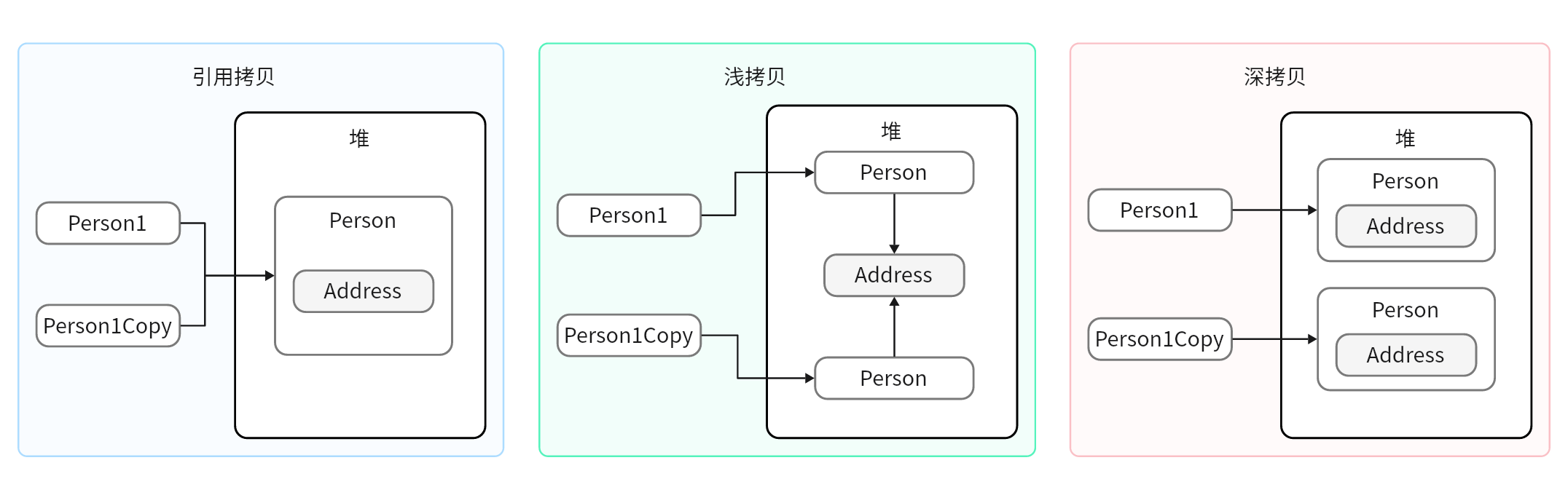
Java深拷贝、浅拷贝、引用拷贝
👍直接举例:有两个对象,一个Person对象和一个Car对象。Person对象有一个属性是Car类型的引用,也就是说这个Person对象“拥有”一辆Car。
浅拷贝:
- 当对
Person对象浅拷贝时,我们只是简单地复制了这个Person对象本身,但它内部的Car类型的引用还是指向原来的那辆Car。 - 换句话说,新的
Person对象和原来的Person对象都指向同一辆Car。如果之后我们修改了任何一个Person对象所指向的Car,那么另一个Person对象所看到的Car也会改变,因为它们都指向同一个Car。
深拷贝:
- 当我们对
Person对象进行深拷贝时,我们不仅复制了这个Person对象本身,还复制了它内部的Car类型的引用所指向的Car对象。 - 也就是说,新的
Person对象拥有一辆全新的Car,这辆Car和原来的Person对象所拥有的Car是完全独立的。如果我们修改了任何一个Person对象所拥有的Car,另一个Person对象所看到的Car不会受到影响,因为它们指向的是两辆不同的Car。
浅拷贝和深拷贝例子:
// Person和Car类如下定义
class Car {
private String model;
public Car(String model) {
this.model = model;
}
}
class Person implements Cloneable {
private String name;
private Car car;
public Person(String name, Car car) {
this.name = name;
this.car = car;
}
// 浅拷贝实现
public Person shallowCopy() {
try {
Person copy = (Person) super.clone();
return copy;
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
}
// 深拷贝实现
public Person deepCopy() {
Person copy = new Person(this.name, new Car(this.car.getModel()));
return copy;
}
}
// 进行操作浅拷贝和深拷贝如下
public class CopyExample {
public static void main(String[] args) {
Car myCar = new Car("Toyota");
Person myPerson = new Person("Alice", myCar);
// 浅拷贝
Person shallowCopiedPerson = myPerson.shallowCopy();
System.out.println("Original car: " + myPerson.getCar().getModel());
System.out.println("Shallow copied car: " + shallowCopiedPerson.getCar().getModel());
// 修改原始Person的Car模型
myCar.setModel("Honda");
System.out.println("Modification, original car: " + myPerson.getCar().getModel());
System.out.println("Modification, shallow copied car: " + shallowCopiedPerson.getCar().getModel());
// 可以看到浅拷贝的Person对象的Car模型也随着原始Person的Car模型的改变而改变,因为它们引用的是同一个Car对象。
// 深拷贝
Person deepCopiedPerson = myPerson.deepCopy();
System.out.println("Deep copied car: " + deepCopiedPerson.getCar().getModel());
// 修改原始Person的Car模型
myCar.setModel("Ford");
System.out.println("Modification, original car: " + myPerson.getCar().getModel());
System.out.println("Modification, deep copied car: " + deepCopiedPerson.getCar().getModel());
// 可以看到深拷贝的Person对象的Car模型没有随着原始Person的Car模型的改变而改变,因为它们引用的是不同的Car对象。
}
}
引用拷贝:
简单地将一个新变量指向原始对象的内存地址,而不是创建一个新的对象。
例如:
class Car {
// Car类的属性和方法
}
class Person {
private Car car;
public Person(Car car) {
this.car = car;
}
// Person类的其他属性和方法
}
// 伪代码操作
Car myCar = new Car(); // 创建Car对象
Person myPerson = new Person(myCar); // 创建Person对象,并将myCar的引用赋给它的car属性
Person anotherPerson = myPerson; // 引用拷贝
上图:
Java中==和equals()的区别
基本数据类型与对象类型:
==:1️⃣对于基本的数据类型,比较两个值是否相等。2️⃣对于对象类型,比较对象内存地址(引用类型)是否相等。(❗注意:因为在 Java 中,只有值传递,所以引用的值传递的是对象的内存地址)equals():用于比较两个对象的内容是否相等。默认情况下,Object 类中的equals()方法与==的行为相同,即比较对象的引用是否相同。
自定义对象:
- 对于自定义对象,如果你没有重写 equals() 方法,那么使用
equals()和==的效果是一样的,都是比较对象的引用是否相同。
空值比较:
- 使用
==可以直接比较两个对象是否为 null,例如obj1 == null。而 equals() 方法则不能用于与 null 进行比较,否则会抛出NullPointerException。
为什么重写equals()时必须重写hashCode()方法?
首先,hashCode()有什么用?
- 快速查找:哈希表通过 hashCode() 生成的哈希值来快速定位对象。
- 数据结构实现:很多 Java 的数据结构(如
HashMap,HashSet,Hashtable,LinkedHashMap等)都依赖 hashCode() 方法。 - 集合中保证唯一性:在 HashSet 、或作为 HashMap 键时,
hashCode()和equals()方法一起确定对象的唯一性。首先,通过 hashCode() 确定对象可能的存储位置;然后,通过 equals() 方法来确定对象是否真的相等。
两个对象有相同的hashCode值并不意味它们一定相等
- 哈希碰撞(Hash Collisions):
- 指不同的对象生成相同的哈希值。这是因为哈希函数将无限大的输入空间映射到有限大的输出空间(通常是整数),所以必然存在多个不同的输入产生相同的输出。
- hashCode() 与 equals() 的关系:
- 在 Java 中,如果两个对象相等(即它们的 equals() 方法返回 true),那么它们的 hashCode() 必须返回相同的值。但是,反过来并不成立:即使两个对象的 hashCode() 相同,它们的 equals() 方法也可能返回 false,这是哈希碰撞的结果。
- hashCode() 在哈希表中的作用:
- 在哈希表中,hashCode() 可快速定位对象存储位置。如果两个对象的
hashCode()相同,那它们初步相等,要进一步通过 equals() 方法比较。如果 equals() 返回 true,则它们相等;如果返回 false,则尽管哈希值相同,它们也为不同的对象。
- 在哈希表中,hashCode() 可快速定位对象存储位置。如果两个对象的
- hashCode() 不相等则对象一定不相等:
- 如果两个对象的 hashCode() 值不相等,可确定这两个对象在哈希表中一定处于不同的位置。我们可以直接认为这两个对象不相等,无需进一步调用 equals() 方法比较。
总结:
- 维护约定:如果两个对象相等,那么它们的 hashCode 值也应该相同。这是Java对象的一个基本约定。
- 哈希表需求:哈希表依赖 hashCode 值快速查找对象。如果不重写 hashCode(),相等的对象可能会有不同 hashCode 值,导致哈希表无法正常工作。
补充(无序性和不可重复性):
- 无序性≠随机性,无序性指集合中的元素在物理存储上并不按照它们被添加到集合的顺序来排列,而是按照哈希值存储的。
- 不可重复性指集合中不能包含通过 equals() 方法判断为相等的元素,需要重写 equals() 和 hashCode() 方法。
String、StringBuffer、StringBuilder有什么区别
1.可变性与不可变性
- String:不可变。一旦创建了一个 String 对象,它的内容就不能被改变。如果对其进行修改,实际上是新建了一个 String 对象,是线程安全的(因为读取操作不会修改 String 对象的状态)。
- StringBuffer 和 StringBuilder:可变的。它们都继承了 AbstractStringBuilder 类,并且这个类使用的是字符串数组来保存,还提供了很多修改字符串的方法,如
append()、insert()、delete()等。
2.线程安全性
- String:由于它是不可变的,所以不存在线程安全问题。
- StringBuffer:线程安全。它对方法添加了同步锁(synchronized)。
- StringBuilder:非线程安全。它的方法都是非同步的,在多线程环境下需要提供额外的同步措施,否则可能会出现数据不一致的问题。
3.性能
- String:由于不可变,每次对字符串进行修改都会新建一个对象,可能会导致大量的内存分配、垃圾回收,从而影响性能。
- StingBuffer、StringBuilder:都有可变的字符串的处理方法,避免了不必要的内存分片和垃圾回收。
- 注意:相同情况下,StringBuilder 比 StringBuffer 性能好,因为没有同步开销。虽然可以提升 10%~15% 的性能,但是要冒多线程不安全的风险。
4.用途:
- String:通常用于存储和处理不可变的字符串。
- StringBuffer:在需要频繁修改且需要线程安全的情况下使用。
- StringBuilder:在单线程下,需要频繁的修改情况下使用。
字符串使用“+”还是StringBuilder拼接?
使用“+”操作符拼接字符串
优点:
- 简单直观:使用“+”操作符直观易读。
- 自动优化:编译器会进行内联优化,直接生成拼接后的字符串。
缺点:
- 性能开销:对于变量或方法调用的复杂字符串拼接表达式,每次使用“+”都会导致创建一个新的
StringBuilder对象(Java 9之前),然后调用append()方法,最后调用toString()来生成结果。这会创建大量临时对象,增加垃圾回收的压力,从而降低性能。
使用StringBuilder拼接字符串
优点:
- 高性能:
StringBuilder在内存中维护了一个可修改的字符数组,通过append()方法添加新内容。避免了拼接时创建新的字符串对象,从而提高了性能。 - 适用复杂场景:对于包含变量、方法调用或循环的复杂字符串拼接场景,
StringBuilder提供了更好的性能和灵活性。
缺点:
- 代码可读性:与“+”操作符相比,使用
StringBuilder的代码可能不那么直观,需要更多的代码行来实现相同的功能。 - 易错性:在使用
StringBuilder时,需要手动调用toString()方法来获取最终的字符串。
总结
- 对于简单的、不频繁的字符串拼接,或者当性能不是关键因素时,使用“+”操作符。
- 对于复杂的、频繁的字符串拼接,尤其在循环中,使用
StringBuilder。
字符串常量池
字符串常量池是Java虚拟机(JVM)为了提升性能和减少内存开销而专门开辟的一块区域,主要用于存储字符串常量。字符串常量池是由 String 类私有的维护,其主要作用是避免字符串的重复创建。
public class Test {
public static void main(String[] args) {
// 这里,字符串"ab"被创建在字符串常量池中
String s1 = "ab";
// 当我们再次使用相同的字面量"ab"时,Java会检查字符串常量池中是否已存在该字符串
// 如果存在,则s2会引用常量池中的同一个对象,而不是重新创建一个新的对象
String s2 = "ab";
// 因为s1和s2都引用常量池中的同一个对象,所以它们比较时(使用==)会返回true
System.out.println(s1 == s2); // 输出: true
// 使用new关键字在堆上创建一个新的字符串对象,尽管它的内容与s1和s2相同
String s3 = new String("ab");
// 因为s3引用的是堆上的一个新对象,而不是常量池中的对象
// 所以s1和s3比较时(使用==)会返回false
System.out.println(s1 == s3); // 输出: false
// 但如果我们使用equals()方法来比较内容,那么s1、s2和s3都会返回true
// 因为它们的内容都是"ab" (String的equals方法比较的是字符串的值)
System.out.println(s1.equals(s2)); // 输出: true
System.out.println(s1.equals(s3)); // 输出: true
}
}
Java中volatile和synchronized区别
1. volatile
一种轻量级的同步机制,它主要有两个作用:
- 可见性:当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主内存,当有其他线程需要读取时,它会去主内存中读取新值。确保了多个线程之间能看到共享变量的最新值。
- 禁止指令重排序:volatile 关键字能禁止指令重排序优化,确保了程序的有序性。
但是,volatile 并不能保证复合操作的原子性。如,对于 i++ 这样的操作,它实际上包含了读取-修改-写入三步骤,而 volatile 不能确保这三个步骤在一个不可分割的、原子性的操作中完成。
2. synchronized
一种重量级的同步机制,它可用来修饰方法或代码块。当一个线程进入一个对象的synchronized(this)方法或代码块时,其他线程对该对象的所有其他synchronized(this)方法或代码块的访问将被阻塞。
synchronized 的作用主要:
- 原子性:synchronized 通过互斥锁的方式保证同一时刻只有一个线程可以执行某个方法或代码块,确保了这些操作是原子的。
- 可见性:当一个线程释放锁时,会将修改后的共享变量的值刷新到主内存。因此,当其他线程获取到该锁时,就可以看到共享变量的最新值。
- 禁止指令重排序:和 volatile 一样,synchronized 也能禁止指令重排序优化。
3. 区别
- 粒度: volatile 用于修饰变量,而 synchronized 用于修饰方法或代码块。
- 原子性:volatile 不保证复合操作的原子性,而 synchronized 可以保证被它修饰的代码块的原子性。
- 性能:volatile 是轻量级的同步机制,性能开销较小;而 synchronized 是重量级的同步机制,性能开销较大。
- 使用场景: volatile 主要用于实现可见性和禁止指令重排序;而 synchronized 则主要用于实现原子性和可见性。