MySQL 索引常见面试题
本文最后更新于 2024-04-22,文章内容可能已经过时。
一、什么是索引?
MySQL 索引是用于提高数据库查询性能的一种数据结构。它类似于书籍的目录,可以帮助我们更快地找到所需的信息。索引能够减少数据库的扫描量,加速查询。
举一个生活中的例子:
假如你在图书馆,里面存放了成千上万的书籍。如果你想要找到一本需要的书,你会怎么做呢?
-
没有索引的情况:
- 从第一个书架开始,逐本检查每一本书,直到找到你需要的那一本。
-
有索引的情况:
- 图书馆提供了一个目录或索引,其中列出了所有书籍的标题、作者和存放位置。
- 你可以直接查阅这个目录,找到书的标题或作者,然后查看它存放位置。
在 MySQL 中,当你执行一个查询时,如果没有索引,MySQL 需要扫描整个表来找到匹配的行,这称为全表扫描。如果有索引,MySQL 可以利用索引来定位到目标的数据行,大大加快查询效率。
二、索引的类型
-
按数据结构分类:
- B+Tree 索引:最常见的索引类型,适用于范围查找和排序操作。
- Hash 索引:适用于等值查询,不支持范围查找和排序操作。
- Full-text 索引:用于全文搜索,支持模糊匹配和关键字搜索。
- R-Tree 索引:用于地理信息系统和空间数据存储。
-
按物理存储分类:
- 聚簇索引(主键索引):数据行按照主键的顺序存储,常用于频繁查询和范围查询。
- 二级索引(辅助索引):指向数据行的指针,通过主键索引进行数据定位。
-
按字段特性分类:
- 主键索引(
PRIMARY KEY):唯一标识一行数据的索引,一般为表的主键。 - 唯一索引(
UNIQUE KEY):保证索引列的唯一性,允许NULL值。 - 普通索引(
INDEX):最基本的索引类型,没有特殊限制。 - 前缀索引(
INDEX(column(length))):只索引列值的前缀部分,可减小索引大小。
- 主键索引(
-
按字段个数分类:
- 单列索引:只包含单个列的索引。
- 联合索引:包含多个列的索引,用于多列查询和排序。
三、为什么 InnoDB 选择 B+Tree 作为索引的数据结构?
- 非叶子节点只存储键值信息:B+Tree 的非叶子节点不存储指向具体数据的指针,而只存储键值信息。
- 叶子节点存储实际的数据:B+Tree 的叶子节点有着完整的记录信息,即指向数据行的指针或数据本身。
- 叶子节点之间通过指针连接:B+Tree 的叶子节点之间通过指针连接(双向链表)。这样可以提高范围查询的效率,因为一旦找到范围的起点,就可以沿着链表快速遍历所有相关的叶子节点,获取所有匹配的数据行。
- 多路搜索树:B+Tree 是一种多路搜索树,每个节点可以有多个子节点。这使得树的高度相对较低,减少了查询过程中的磁盘 I/O 操作次数。
四、什么时候需要创建索引?
- 查询频繁、数据量大:经常出现在 WHERE 子句、JOIN 操作或 ORDER BY 子句中的列。
- 唯一性约束:某列的值需要保证唯一性时,比如商品编号。
- 经常用于排序的列:某列经常用于 ORDER BY 子句进行排序,比如注册时间。
五、什么时候不需要创建索引?
- 数据更新频繁的列:在数据更新(如
INSERT、UPDATE、DELETE)时,索引要进行维护。如果某列的数据更新非常频繁,那么维护索引的开销可能会超过查询性能。 - 存在大量重复值的列:比如性别字段,只有男女。因为当某个值在表中的出现频率非常高时,查询优化器会决定不使用索引,而直接进行全表扫描。
- 小表:表数据太少的时候,不需要创建索引。
- 很少用于查询的列:索引会占用额外的磁盘空间,增加维护成本。
六、有什么优化索引的方法?
- 前缀索引优化:有过长的字符串类型的字段,可以只对前缀部分进行索引,减小了索引字段大小,提高查询效率。
- 覆盖索引优化:当查询所需的所有数据都包含在索引中,数据库仅通过扫描索引来满足查询,而无需回表去访问实际的数据行。这种索引被称为覆盖索引,减少了大量的 I/O 操作。
- 主键索引应该是自增的:可以确保每次插入新数据时,数据库能够按顺序将数据添加到索引的末尾,而不需要移动已有数据。如果使用非自增主键,如 UUID,那么每次插入数据时都可能需要重新排列索引中的数据,效率很低。
- 防止索引失效:
- 避免在索引列上使用函数或计算表达式。
- 确保查询条件中的数据类型与索引列的数据类型一致。
- 避免使用NOT操作符和OR条件。
- 避免使用模糊查询,如
like %xx和like %xx%。 - 联合索引要正确遵循最左匹配原则。
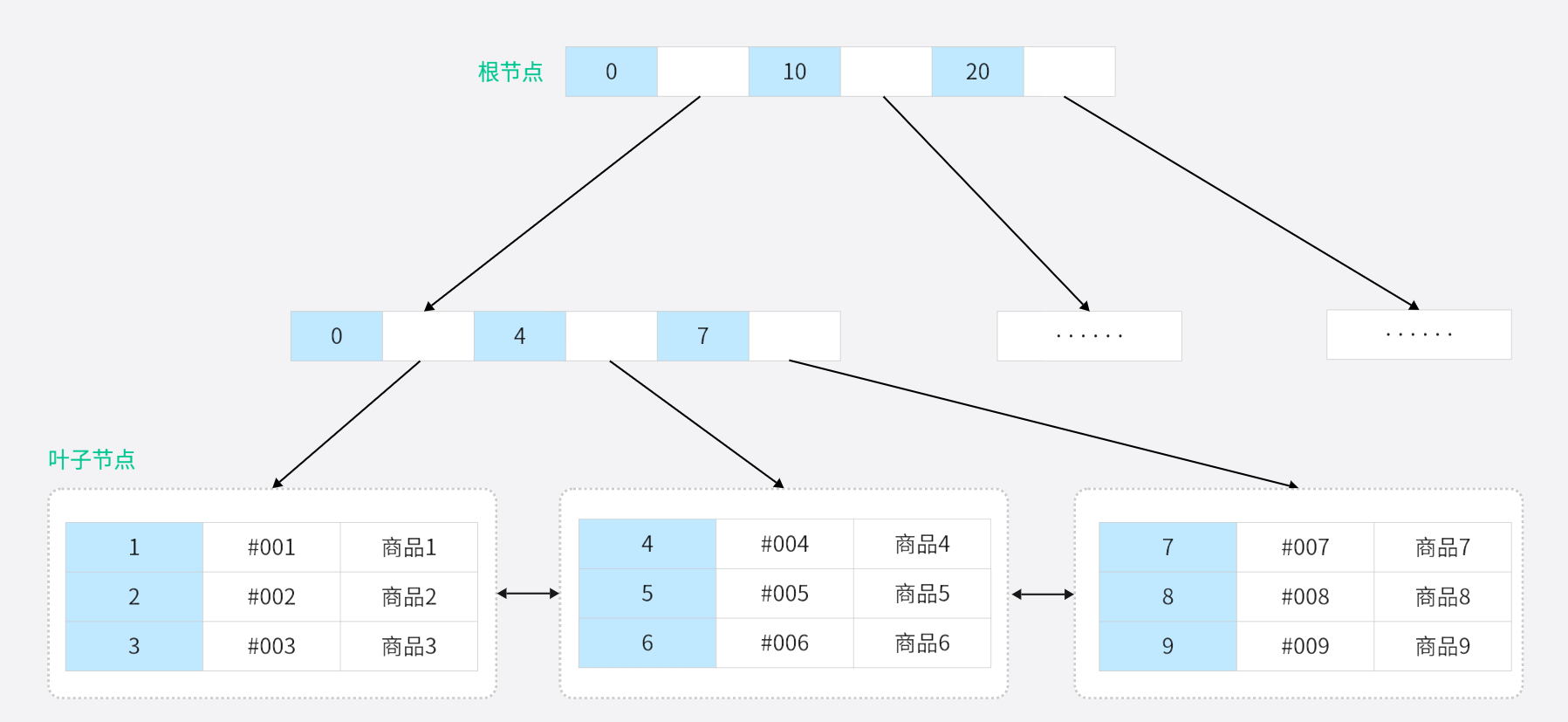
七、B+Tree 大概的样子
八、COUNT(*) 和 COUNT(1) 有什么区别?
在MySQL中,COUNT() 是一个聚合函数,它的参数可以是字段名,也可以是其他任意表达式。当你在查询中使用 COUNT() 函数时,它会对指定列的非 NULL 值进行计数,并返回计数结果。
COUNT() 函数参数:
-
COUNT(*):计算表中所有行的数量,不考虑列的值是否为 NULL。
-
COUNT(列名):计算指定列中非 NULL 值的数量。如果列中的某个值是 NULL,那么这一行不会被计入总数。
-
COUNT(DISTINCT 列名):计算指定列中不同非 NULL 值的数量。可以用来查找列中的唯一值数量。
-
COUNT(表达式):表达式可以是一个计算字段,一个常量,或是一个更复杂的表达式。COUNT() 会计算表达式结果不为 NULL 的行数。
COUNT() 性能排序:
- COUNT(*) = COUNT(1) > COUNT(主键列名) > COUNT(列名)
九、那么它们有什么区别呢?
在大多数情况下, COUNT(1) 与 COUNT(*) 在性能上相差无几,因为MySQL优化器通常能够识别这种用法,并进行优化。
-
COUNT(*):
-
COUNT(*) 计算表中的所有行数,包括NULL值。
-
在执行时,MySQL不会对每一行进行全表扫描来判断其是否为NULL,而是直接读取行数。所以,它在性能上是比较高效的。
-
COUNT(1):
- COUNT(1) 也是对表中的行数进行计数,其中“1”是一个常量表达式。
- 在内存中为每一行分配的唯一标识符。
- 在统计结果时,也不会忽略NULL值。